本篇博文使用python爬虫爬取百度图片
很久没有写py爬虫了,爬取百度图片的也是之前写的,今天发出来记录一下!供自己学习!
项目:实现搜索百度图片进行批量下载图片
环境:python3.7 + pycharm
先简单说一下这个项目。当你需要下载大量图片的时候,可能你会去百度图片中一张张下载,但是这样未必太麻烦了。有了这个程序,直接运行程序输入你想要下载图片的关键词,就可以实现批量下载图片。
下面是程序的截图: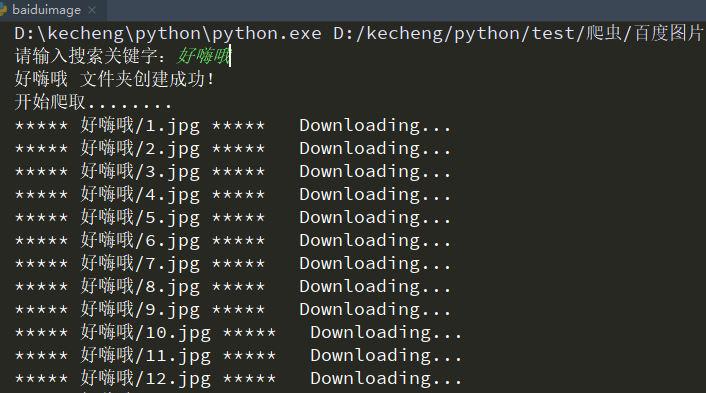
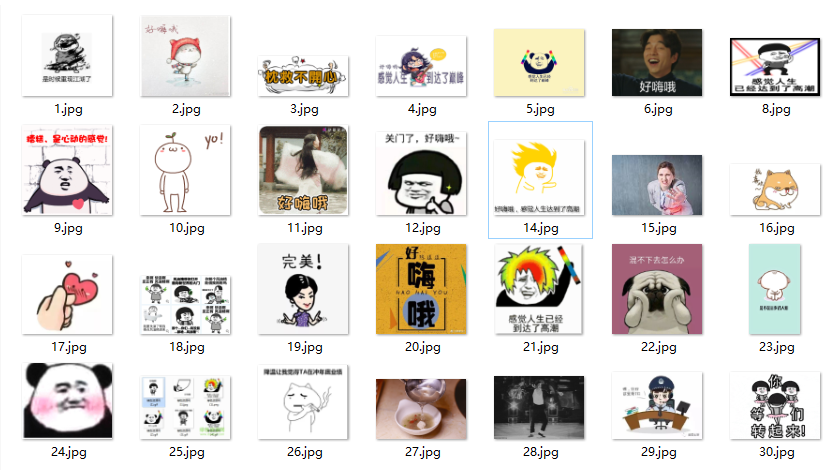
一下子就下载了30张关于‘好嗨哦’关键词的图片,是不是觉得这样下载比较方便….
好了,回到主题,怎么一步步实现它!
1.安装python教程,这里推荐一个小白教程:
2.python的IDE,我想大家应该都有吧!我用的是pycharm,大家可以直接到官网下载官网链接
3.安装爬虫需要使用到的包:
如果你配置的python的环境变量,那么你可以直接cmd
键入 pip install requests
pip install re
pip install os
4.下面将分别介绍它们的用途
requests:请求包,用于向url发送请求获取网页信息
re:正则表达式包,具体详细的知识可以到这里去看python正则表达式
os:处理文件和目录的包
下面介绍技巧:
首先,我们打开百度图片,然后你可以输入你想要查看的图片,我这里搜索‘好嗨哦’
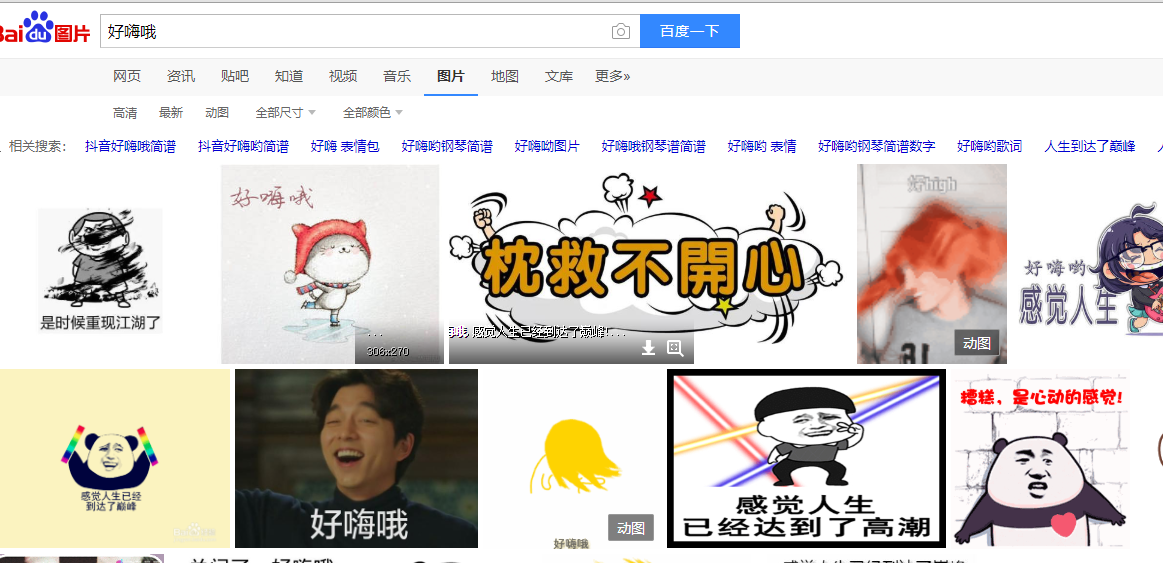
接着,右键查看网页源代码(谷歌浏览器),直接搜索objURL
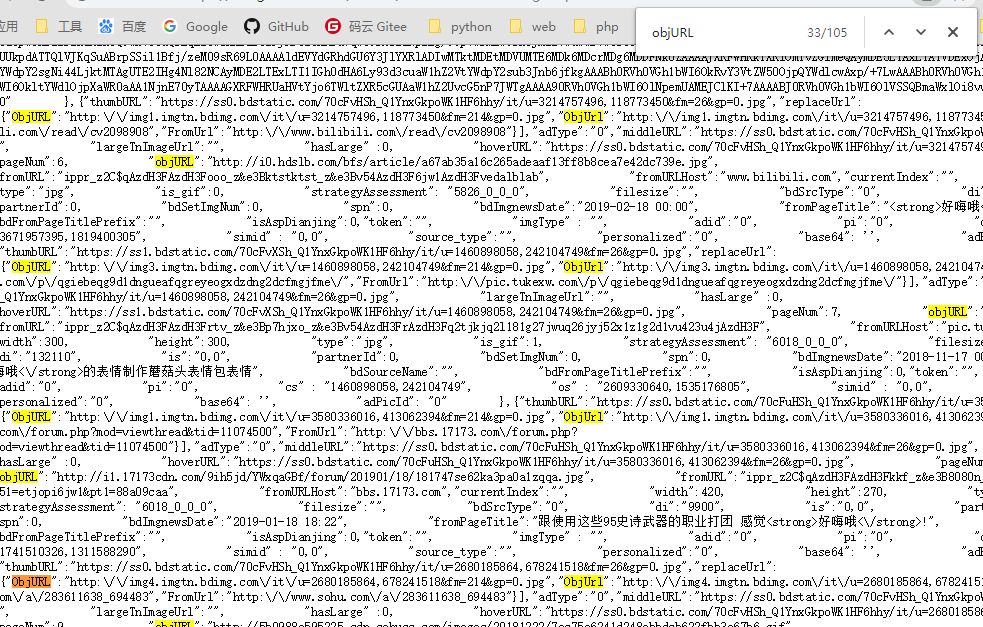
现在我们可以看到这个objURL就是图片的url,现在我们就是要把这些url拿下来。
我们使用正则表达式把,只需一行代码就可以把这些url拿下!

成功拿些这些url,我们就可以用requests包去请求进行下载

其实具体思路就是:分析网页->匹配图片url->下载完成
源代码:
1 | import requests |

